GITA: Graph to Visual and Textual Integration Framework
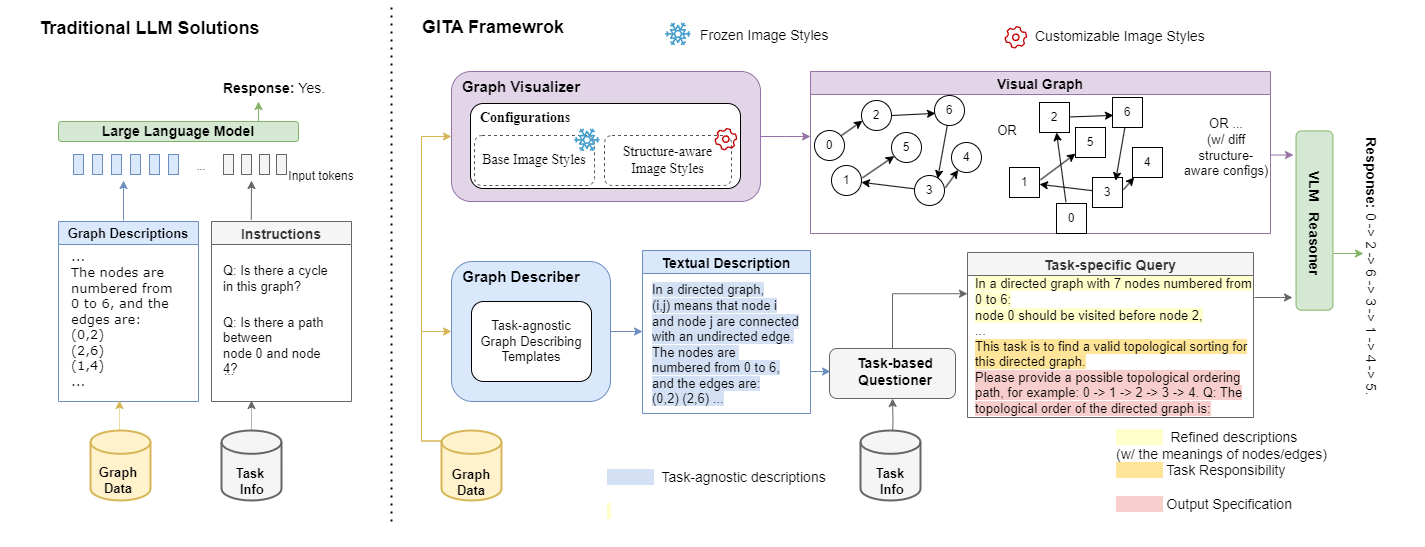
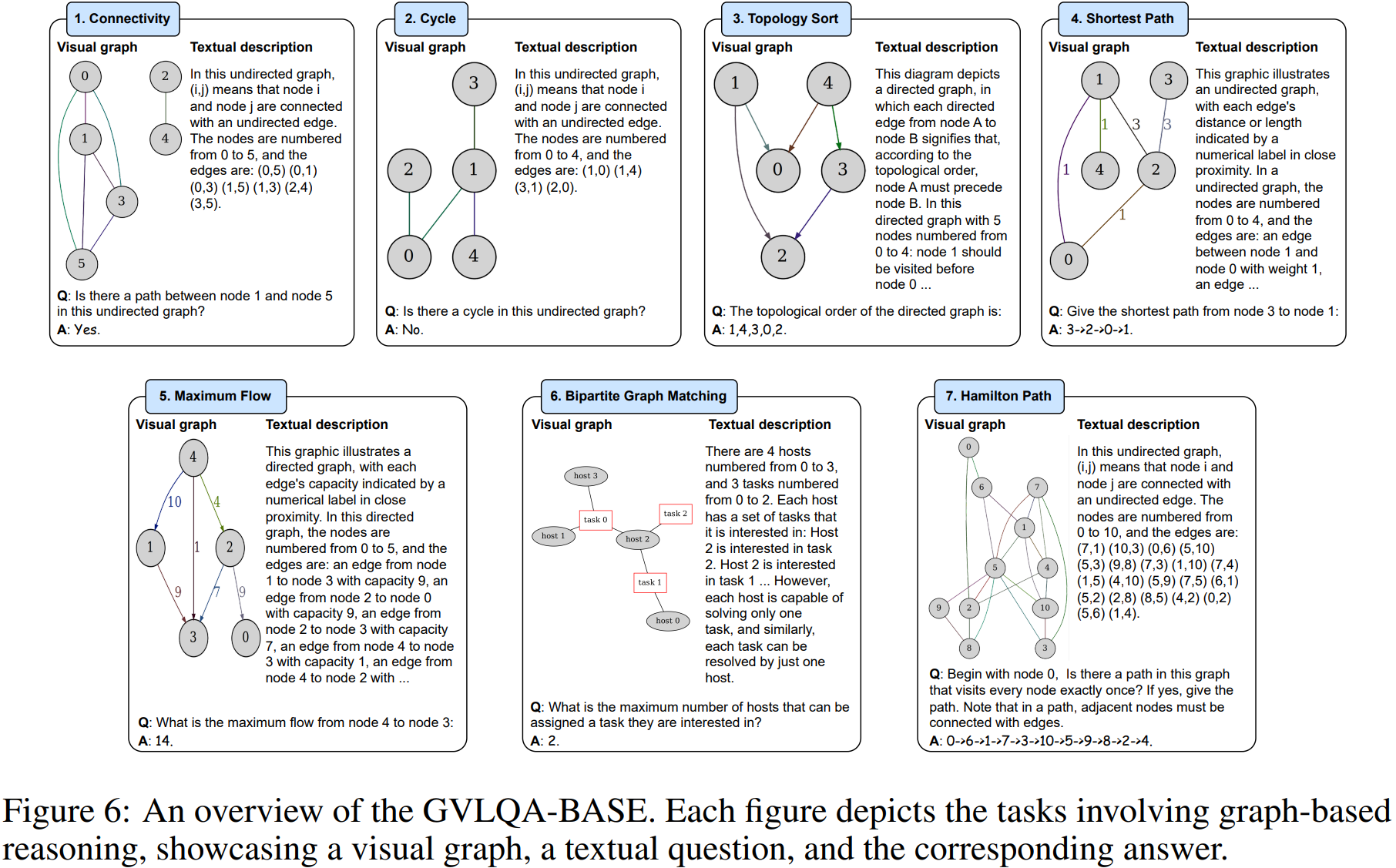
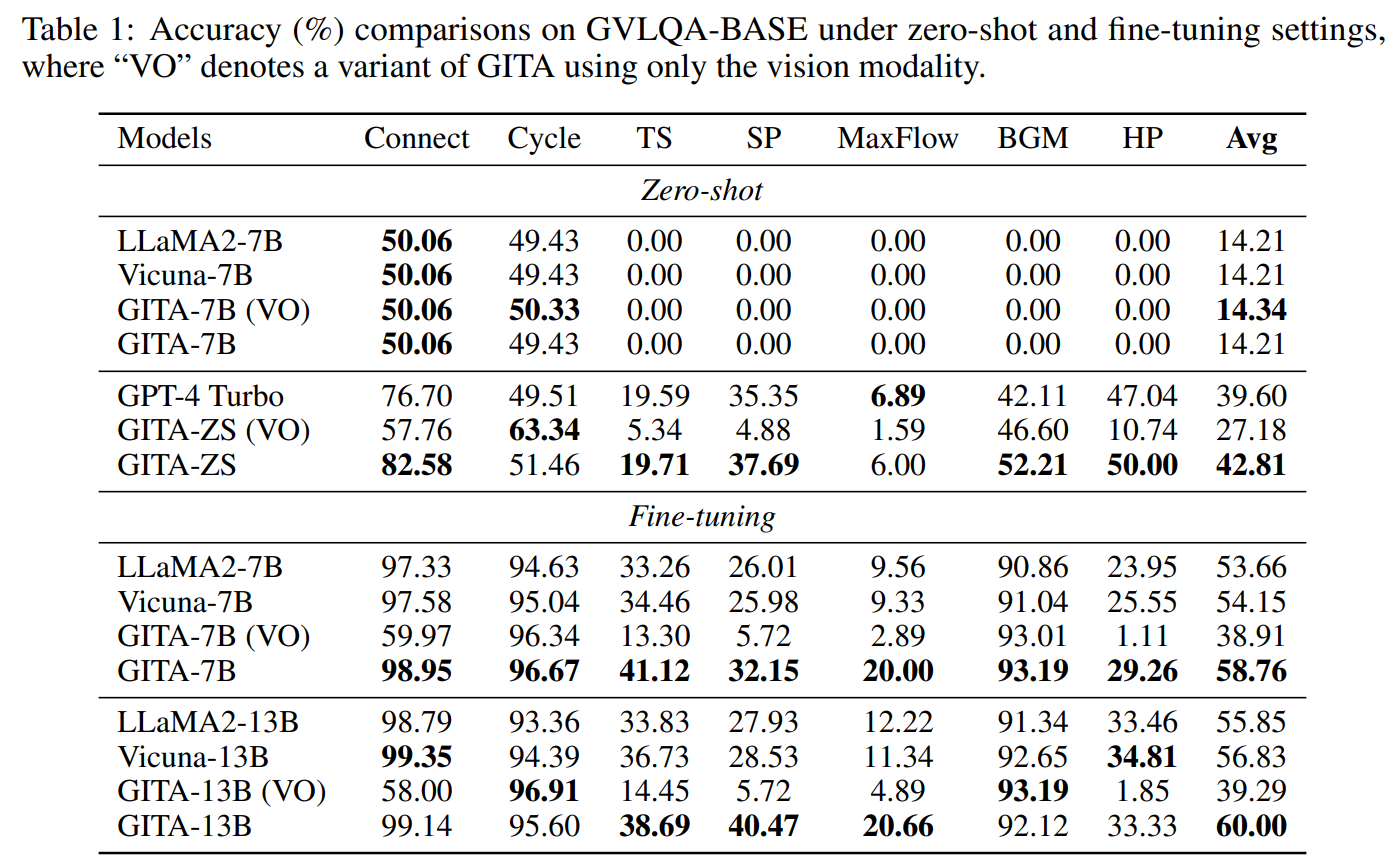
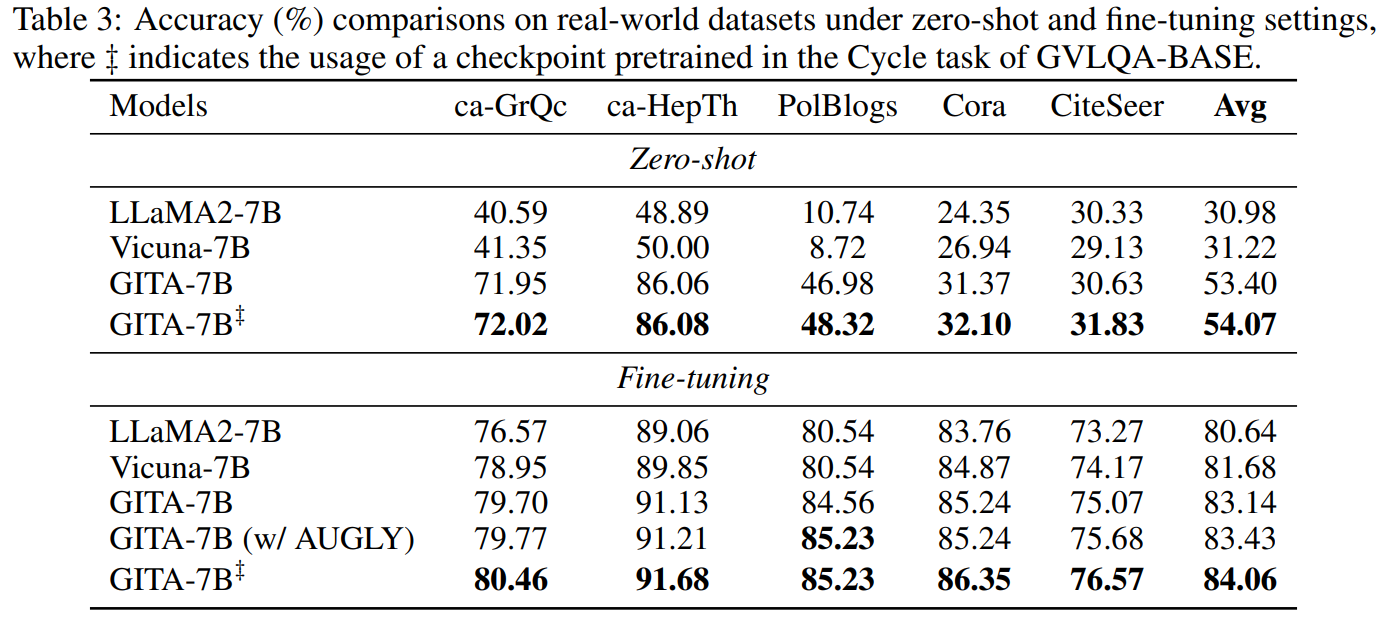
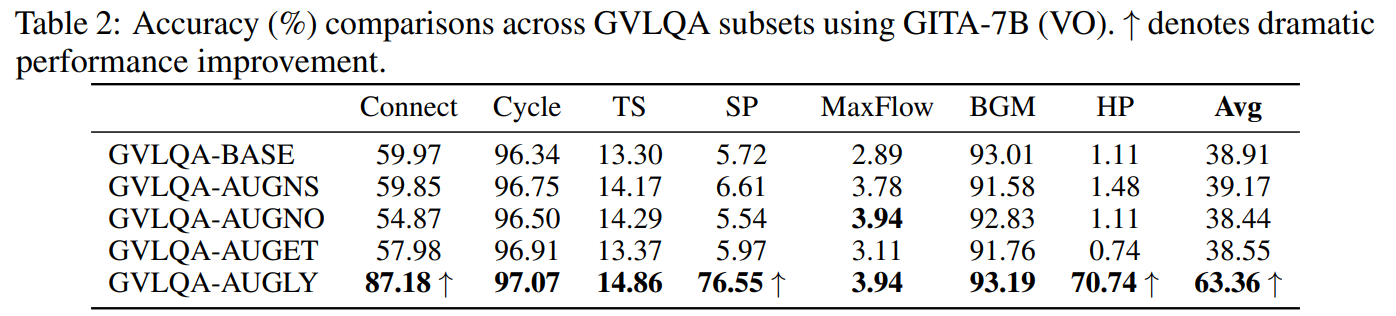
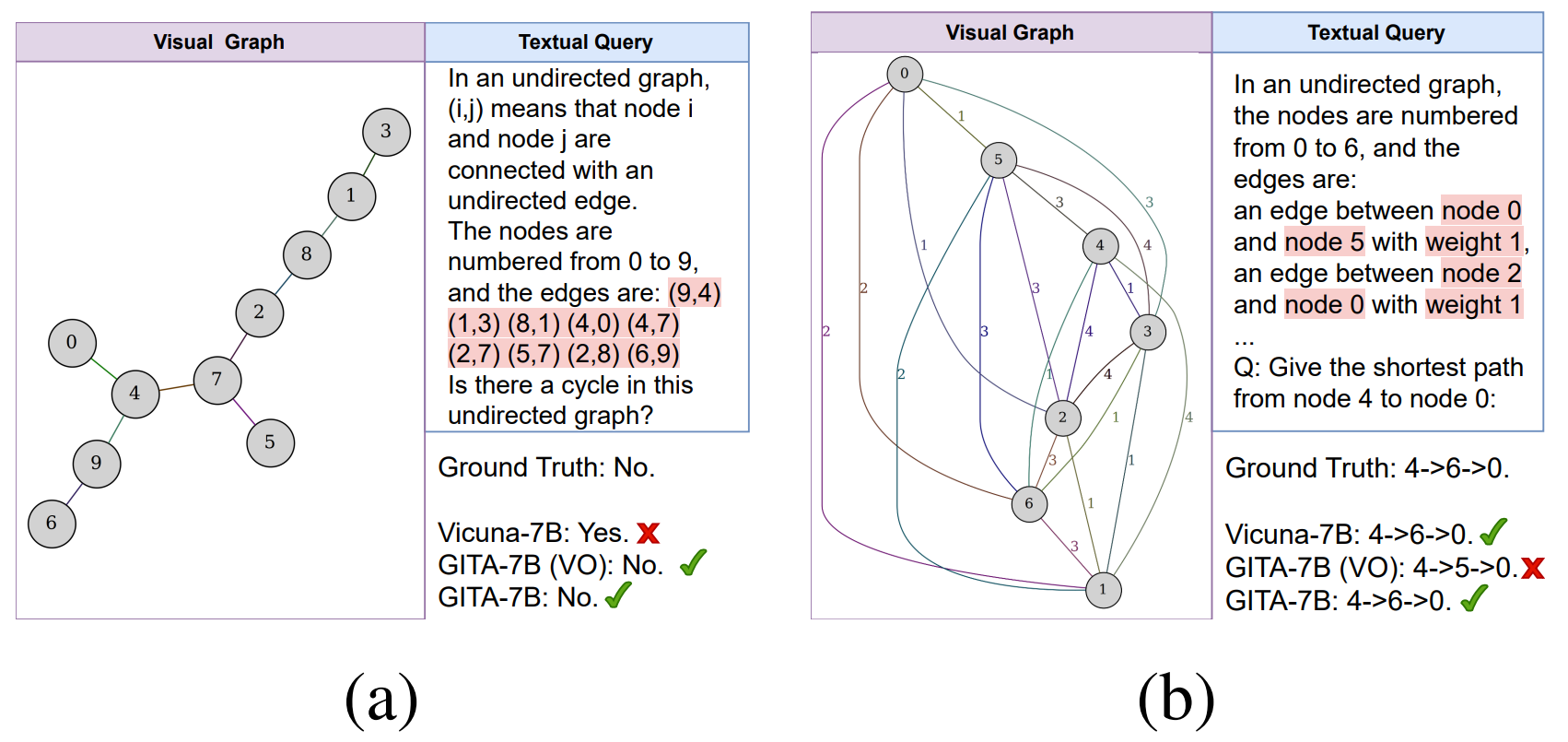
Large Language Models (LLMs) are increasingly used for various tasks with graph structures. Though LLMs can process graph information in a textual format, they overlook the rich vision modality, which is an intuitive way for humans to comprehend structural information and conduct general graph reasoning. The potential benefits and capabilities of representing graph structures as visual images (i.e., visual graph) are still unexplored. To fill the gap, we innovatively propose an end-to-end framework, called Graph to vIsual and Textual IntegrAtion (GITA), which firstly incorporates visual graphs into general graph reasoning. Besides, we establish Graph-based Vision-Language Question Answering (GVLQA) dataset from existing graph data, which is the first vision-language dataset for general graph reasoning purposes. Extensive experiments on the GVLQA dataset and five real-world datasets show that GITA outperforms mainstream LLMs in terms of general graph reasoning capabilities. Moreover, We highlight the effectiveness of the layout augmentation on visual graphs and pretraining on the GVLQA dataset.
@inproceedings{wei2024gita,
title={Gita: Graph to visual and textual integration for vision-language graph reasoning},
author={Wei, Yanbin and Fu, Shuai and Jiang, Weisen and Zhang, Zejian and Zeng, Zhixiong and Wu, Qi and Kwok, James and Zhang, Yu},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024}
}